4.7 Exercises
Natural Gas Usage and Temperature (**): Use the data
indyheatingfor this exercise. Construct a scatter plot with temperature on the horizontal axis and natural gas usage on the vertical axis. What do you observe? How would you expect the graph to look like if electricity consumption was on the vertical axis?Exempt Organizations (***): Consider the data in
exemptorgs. You are going to calculate the average revenue across the so-called NTEE codes. Proceed as follows:- Subset the data such that you are only left with the columns \(revenue\) and \(ntee\).
- Use the function
na.omit()on the data set you created in (a). What is the function used for? - Use the function
aggregate()and calculate the mean assets, revenue, and income by NTEE code. The table created in your answer should contain the NTEE codes in plain English, that is, not the alphabetical codes.
GSS Two-Way Table (**): In the data set
gss, pick two of the following variables: \(fulltime\), \(government\), \(married\), \(vote\), \(gun\), \(deathpenalty\). Construct a cross-table similar to the one about gender and guns in the section Introduction to R. using the functionCrossTable(). Ignore the Chi-square statistic but explain if you see any pattern that is of interest.Airport Delays Boxplot (***): Pick an airport (not IND) and year of your choice in the data set
airlines. You should be using the functionsubset()to pick year and airport. Next, add a column called \(delay\) which is the share of delays from all the arriving flights. Next, construct a boxplot with all the airlines on the x-axis, i.e., one boxplot, and the variable \(delay\) on the vertical axis. Interpret the boxplot. Are there airlines which are particularly on time or always late?Housing Price Index (***): Pick one of 49 U.S. States (not Indiana). Go to the FRED webpage and download two data series: (1) All-Transactions House Price Index for the United States (USSTHPI) and (2) All-Transactions House Price Index for the state of your choice. Answer the following questions.
- What do the two data series describe?
- Plot the two data series over time. Your result should look similar to Panel (b) in Figure \(\ref{fig:SUM_exercises}\).
- How do the housing prices evolve in your state compared to the United States. Do homes in your state get more expensive than the general trend? Less? How has the housing market evolved during and after the 2008 recession?
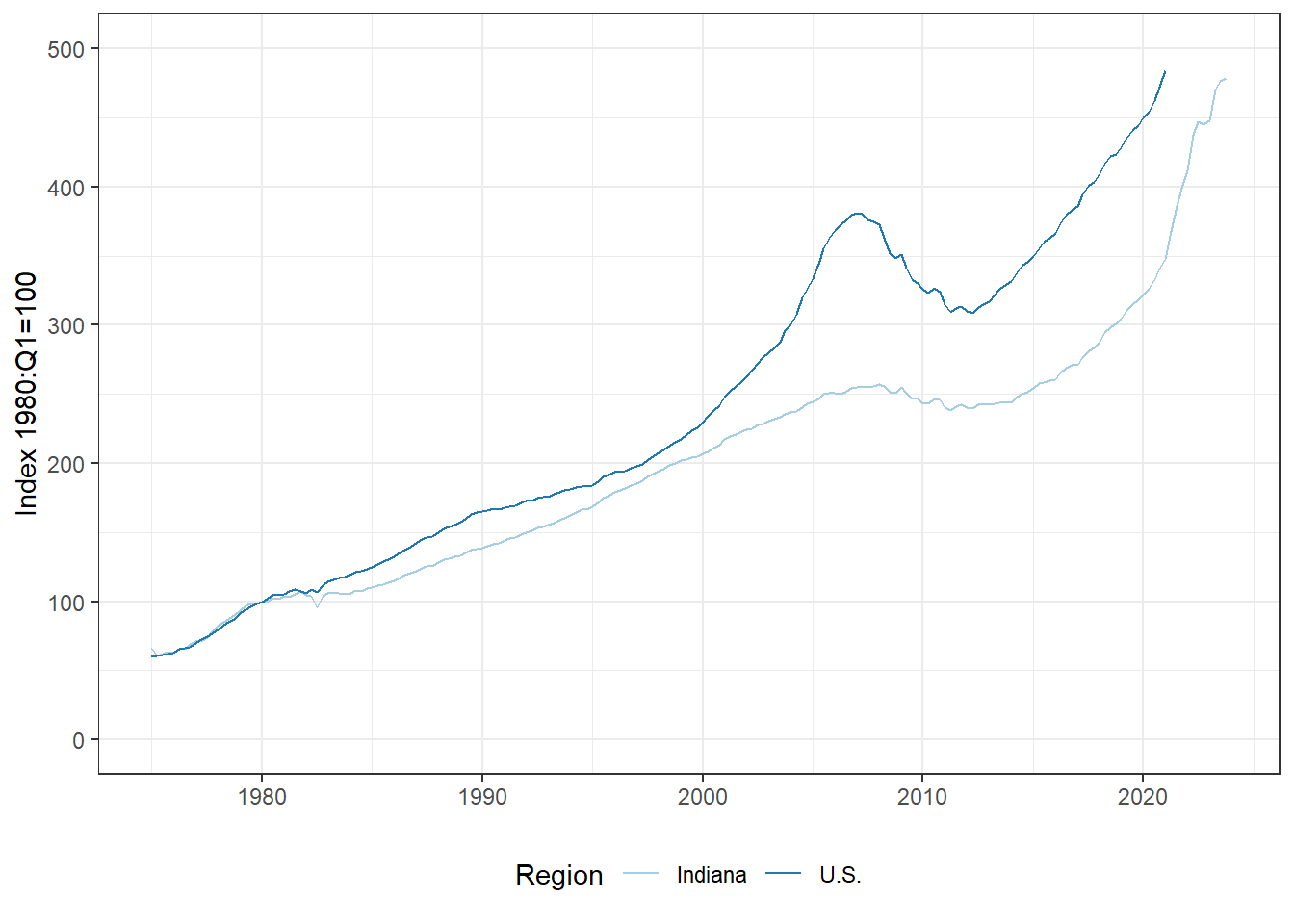
Figure 4.7: Evolution of the All Transaction House Price Index for the U.S. and Indiana (Source: FRED St. Louis)
BMW Boxplot (**): Consider the used car data set
bmwfor this exercise which contains the prices and miles of a particular BMW model in the Indianapolis area. The column \(allwheeldrive\) indicates whether the car has all wheel drive (1) or not (0). You must use the R/RStudio commands and not just look at the data. Answer the following questions:- Calculate the following statistics for price and miles: Minimum, maximum, median, and mean.
- Calculate the same statistics as in the previous part but separate the data into two groups: (1) with all-wheel drive and (2) without all-wheel drive.
- Use the data on prices only. Create a box-and-whisker plot grouped by all-wheel drive. This must be one graph.
State Capitals (**): The data
apartmentscontains data about the monthly rent and size of furnished apartments in Berlin and Potsdam, which are not only adjacent cities but are also capitals of two states in Germany. Add a column that shows the rent per square meter. Then, construct a box plot of the rent per square meter on the y-axis and the location on the x-axis. Based on the boxplot, how does the rent per square meter differ between the two cities. Any other observation, which you are able to make?EPA Fuel Economy (**): Use the 2018 data contained in
vehiclesfor this problem.- Generate a scatter plot of the variables
displandcomb08U. What can you say about the shape of the scatter plot and the relationship between engine displacement and fuel economy. - Transform both variables into their natural logarithm and plot the scatter plot. What changes?
- Create a table summarizing the average fuel economy by vehicle class (\(vclass\)) for the following four manufacturers: (1) Ford, (2) Chevrolet, (3) Toyota and (4) Honda. You will have to use the function
aggregate()for this.
- Generate a scatter plot of the variables
GSS Trends (**): The General Social Survey is an annual survey tracking societal trends in the United States. For a more detailed description, you can go to here. In this exercise, I want you pick a particular issue and one breakdown (e.g., age, sex, political affiliation) and plot a graph with R/RStudio on how attitudes about the issue have evolved over time. I suggest, you go to trends and pick a topic you are interested in. You will see that the website already provides you with a trend graph but I want you to use R/RStudio for this exercise and re-create the graph (i.e., you get zero points if you simply copy the graph provided on the website). For example, suppose you are interested in the variable which asks the respondent ``Do you feel that the income from your job alone is enough to meet your family’s usual monthly expenses and bills?’’ One of many possibility to plot this with R/RStudio would look like Panel (b) in Figure \(\ref{fig:SUM_exercises}\). Make sure to label the \(x\),\(y\)-axis correctly as well as provide a legend for the graph.
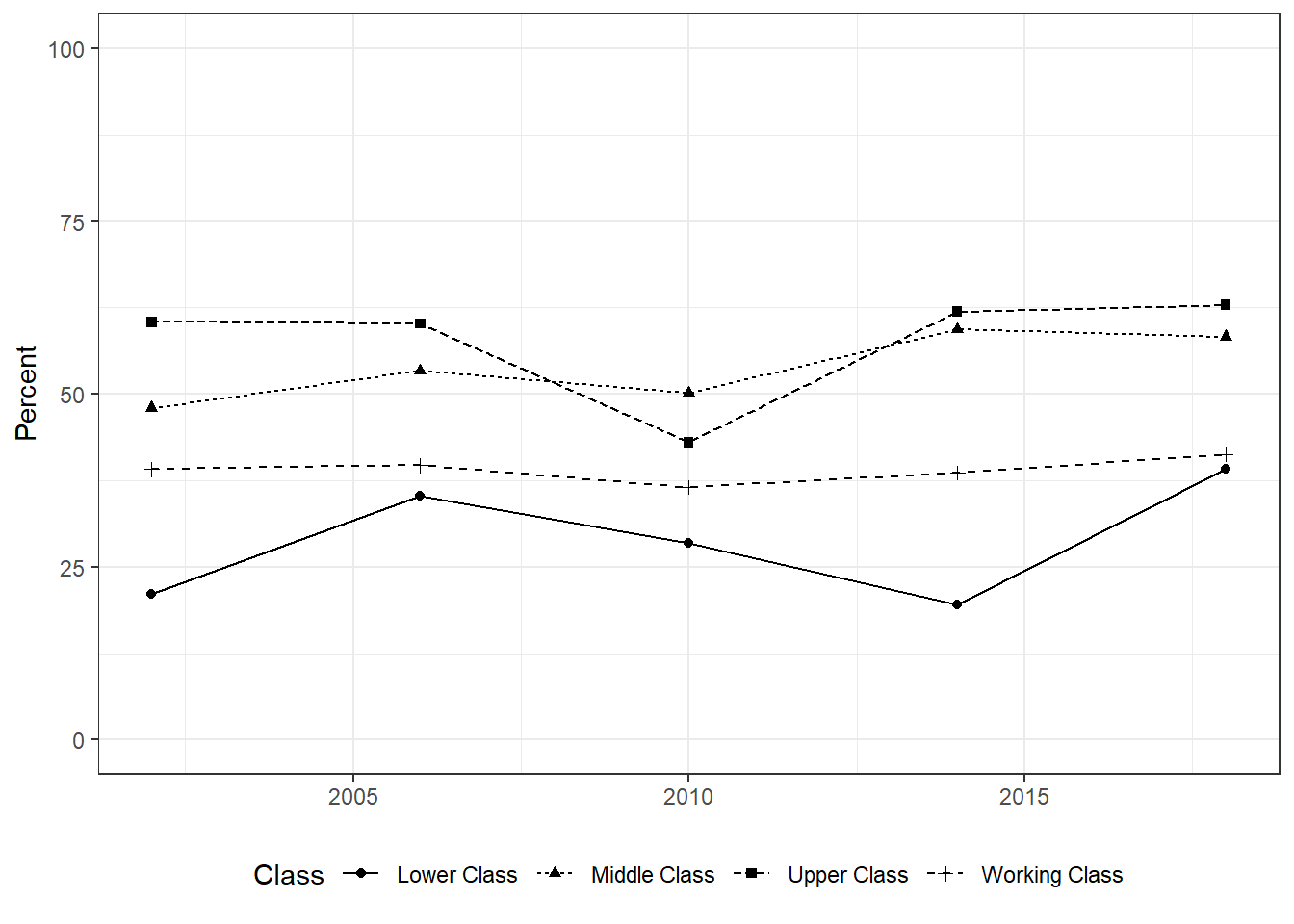
- WDI Boxplot (**): The World Bank data
wdicontains development indicators and also information how the World Bank classifies those countries by region and income. Focus on the years 1975, 1985, 1995, 2005, and 2015 for this question. Use the commandsubset()to extract those years. Next, you have to install and load the packagegglpot2. The packageggplot2allows you to do some great data visualization. Execute the commands below. The result is a boxplot by region and by year. Based on the resulting plot, explain differences between regions in terms of life expectancy and also in terms of evolution over time.
wdiofinterest = subset(wdi,year %in% c(1975,1985,1995,2005,2015))
ggplot(wdiofinterest,aes(x=region,y=lifeexp,fill=as.character(year)))+
geom_boxplot(position=position_dodge(1))Faithful (**): The data set
faithfulwhich is included with R contains data about the eruption and waiting times in minutes between eruptions from Old Faithful geyser in Yellowstone National Park. Use a scatter plot to visualize the relationship between eruption and waiting time. That is, generate graph with \(eruption\) on the vertical axis and \(waiting\) on the horizontal axis. What do you observe? What is the correlation coefficient? Is there anything odd in the resulting scatter plot? Next, use R to construct a empirical cumulative distribution function.Financial Health (***): Consider the data in
statefinhealth. Execute the following commands requiring the package corrplot and include the resulting figure in the homework. What does the plot display? Explain the relationship between the components. Are some of the results surprising?
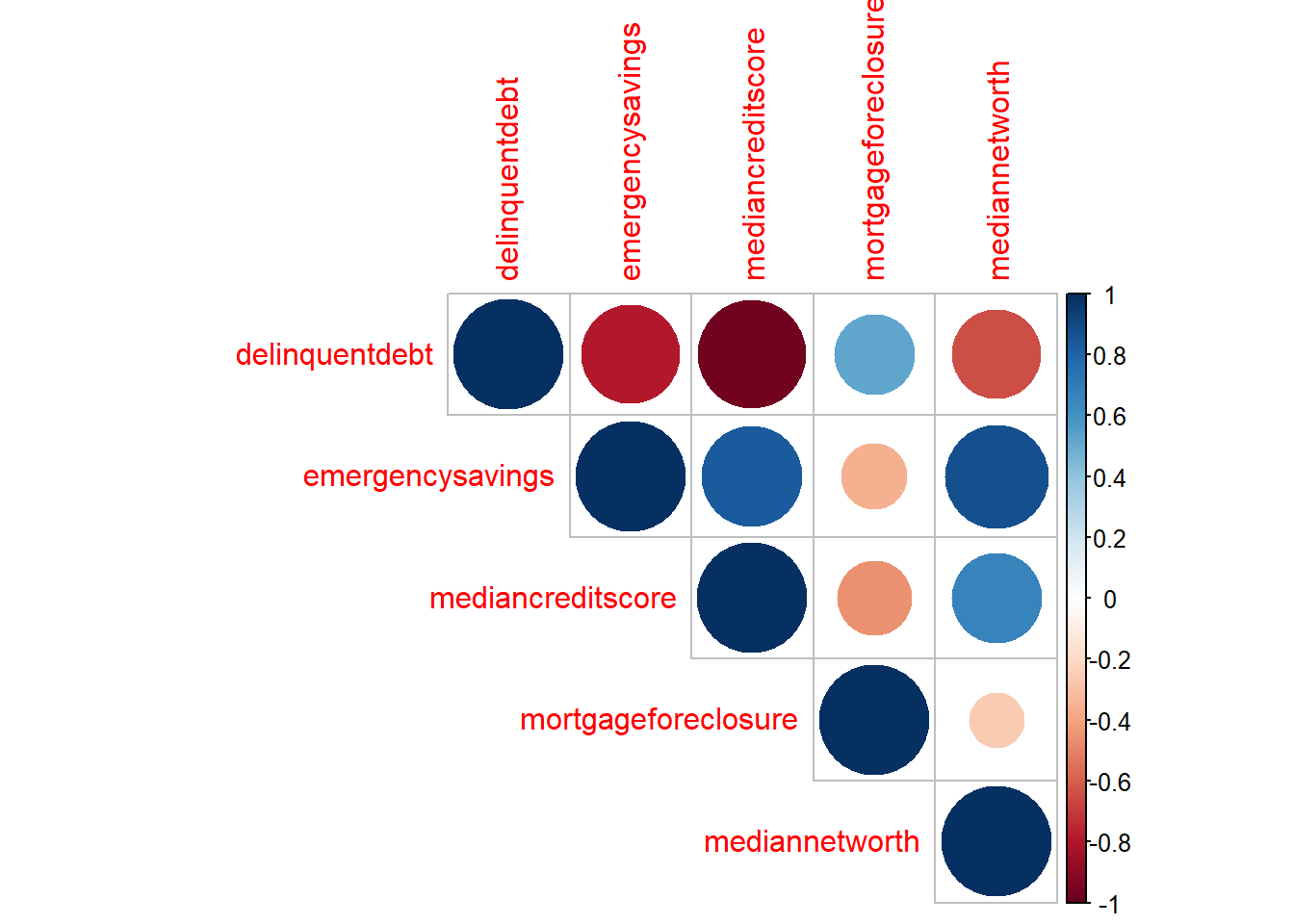
Earnings (***): Consider the data in
earnings, which contains the real earnings by education level, sex, and race/ethnicity. Generate a line plot using the packageggplot2with year on the horizontal axis and the earnings (\(value\)) on the vertical axis. Consider “All Races” but differentiate by education level and sex. That is, differentiate the various education levels with colors and use the ggplot component “+facet_grid()” to plot three graphs side-by-side, i.e., both sexes, men, women. Repeat the exercise using the variable \(growth\).Power Generation (***): Each year, the U.S. Energy Information Administration (EIA) publishes data about all electric generators in the United States. You will find selected variables for all observations of that data in
eia. Use the function “unique()” from R to determine the technologies used in the EIA report. You will see that there are multiple technologies using wind and solar (e.g., offshore wind, onshore wind). The goal of this exercise is plotting the share of wind and solar from the total generation capacity in the state. For this exercise, you will have to use multiple functions, e.g., aggregate(), merge(), to arrive at the final result. Plot the resulting share using the function “ggplot()” from R. California is usually considered the leader in renewbale power generation. Is that still true when considering the share of installed power?